이 글의 목표
- 객관적인 성능 평가 지표로 RAG 시스템 설계 평가하기이 글에 담긴 내용
- 허깅페이스 모델카드 이해하기- 벤치마크
- 모델 평가 기준 (F1, Accuracy, recall, em ... )
- LLM as a judge
지금까지는 눈으로 직접 데이터를 확인하면서 챗봇이 맞는 말 하는지 아닌지 확인했다.
그런데... 데이터가 몇만 몇억개면 어쩔텐가.. 객관적인 지표로 품질을 평가할 수 있는 지표가 있다.
이번 포스팅에서는 LLM평가 객관적인 지표로 사용되는 개념들을 확인하고 취사선택하여 지금까지 만든 시스템 평가에 활용할 것이다.
일단 허깅페이스 모델카드를 이해해보자
https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct
meta-llama/Llama-3.2-3B-Instruct · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
인트로 설명
현재 프로젝트에서 사용하고 있는 메타의 작은 Llama모델. Transformer 호환.
Agentic retrieval과 summarization을 포함한 multilingual dialogue use cases에 최적화된 모델. SFT(지도학습 튜닝) 과 RLHF(사람쓰는강화학습튜닝) 을 거쳐 helpfulness와 safey에 대한 선호도를 평가했다고 한다.
English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai are officially supported
라는데 이 8 개보다 더 광범위한 언어집합으로 훈련되었다고 하니 한국어로도 어느정도 성능을 낸다. 그러나 보다 나은 품질 향상을 위해 한국어 파인튜닝을 한다 하면 메타 커뮤니티 라이센스 및 정책 동의를 따라야 한단다. Apache 2.0
Grouped-Query attention (GQA)
여러 쿼리가 하나의 키밸류 그룹을 공유해서 메모리 사용 줄이고 추론 속도는 높이면서 정확도 손실을 최소화 한, 대규모 추론 최적화 기술을 사용했다.
intended use cases는 어시스턴트 챗봇, knowledge retrieval 및 요약하는 에이전틱 어플리케이션, 자연어 생성 그리고 양자화된 모델을 쓰면 모바일뿐만 아니라 다양한 온디바이스 use cases에 컴퓨팅 리소스를 많이 잡아먹지 않고도 쓸수있단다. 그러나 법률관련 지식은 커버 안되고 라이센스 사용동의를 했기 때문에 해당 정책에 위배되는 목적으로사용 안됨.
9 trillion tokens of data를 사용했는데 작은 모델인 1b 와 3b 의 경우 큰 모델인 8b 와 70b이 낸 logits을 같이 참고해서 큰 모델들이 언제 어떤 걸 얼마나 선호했는것까지 트레이닝시킴. 컷오프는 2023년 12월. 이후 사건에 대해선 원칙적으로 모르고 추론으로 답함.
쓰는 법
import torch
from transformers import pipeline
model_id = "meta-llama/Llama-3.2-3B-Instruct"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])근데 트랜스포머 4.43.0 이상이어야 하니 pip install --upgrade transformers 필.
사용법에 대한 자세한 내용
https://github.com/huggingface/huggingface-llama-recipes
GitHub - huggingface/huggingface-llama-recipes
Contribute to huggingface/huggingface-llama-recipes development by creating an account on GitHub.
github.com
벤치마크
벤치마크는 모델을 평가하는 정량적인 도구로, 다양한 상황과 목적에서 얼마나 답을 맞출 수 있는지를 평가한다.
| 지표 이름 | 설명 | |
|---|---|---|
| Perplextity | 난해함의 정도로, 점수가 낮으면 정확도 높음 | |
| BLEU | 0~1, 1에 가까우면 사람이 작성한 텍스트와 유사성이 높으나 문맥고려 없음 | |
| MMLU | Massive Multitask Language understanding : 57개 과목, 다양한 난이도에 대한 종합적 이해도 평가 | |
| AGIEval English | 전문화되고 복잡한 상황에서의 평가 | |
| ARC-Challenge | 과학적 추론 능력 평가 | |
| SQuAD | Stanford Question Answering Dataset : 글 독해 잘하는지 평가 위키피디아 읽고 답 발췌 | |
| QuAC | 구조화된 대화 상황에서 답 찾아내는지 평가 | |
| DROP | 위에서 독해력 수리력 동시 요구 | |
| needle in haystack | 긴 맥락에서 얼마나 잘 찾는가 |
대표 메트릭
F1 : precision & recall 조화평균 ( 답이 o 100개 x 100 개인데 모델이 200개 다 o라고 했을 경우 답 100개 다 맞췄다고 성능이 높아지는 걸 방지해줌
em : exact match 완전일치하는지 안하는지
acc_char : 문자 단위로 정확도 평가
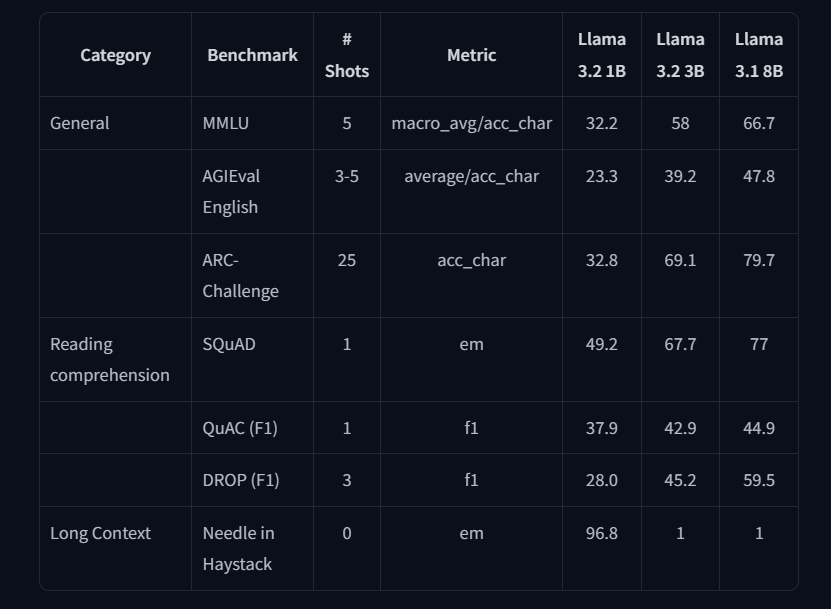
Shots의 수는 얼마나 많은 예제 문제를 제공했는가를 의미한다. 당연하게(?)도 더 큰 모델일 수록 높은 성능을 내는 걸 알 수 있다.
그러나 이것들을 잘 살펴보면.. .정답을 찾는지 못 찾는지에 집중한다.
생성형 모델의 경우 말을 이렇게 표현할 수도 저렇게 표현할 수도 있는 건데 맞고 틀리고를 어케 평가하나???
내 상황에 대입했을 때
문제 : 이 사람의 강점 요약
답1 : 다양한 환경에서 프로젝트 경험이 있고...
답2 : 실제 문제를 해결해 본 경험이 있고...
옵션 1. EM
둘 다 답이 될 수 있지만 EM 으로 하면 false임.
옵션 2. Semantic match로 하면 어떨까?
문장을 임베딩했으므로 코사인 유사도를 비교할 수 있다. bertscore를 사용해 의미적 유사도를 비교해본다.
0은 완전 반대 의미를 , 1은 완전히 일치함을 의미한다.
해답 같아보이지만 이건...
답 1 : 파이썬을 활용할 수 있다
답 2: 파이썬만 활용할 수 있다
뭐 이런 아 다르고 어 다른 상황을 캐치 못한다.
옵션 3. LLM as a judge
다른 모델을 사용해서 이 답이 맞는지 확인할 수 있다! 단순히 맞는지 안 맞는지를 확인하는 걸 떠나서 hallucination정도, 관련성 정도, 개인정보 식별 등도 활용 된다. 스타일, 사실성, 유해성 체크 등등...
생성시
- faithfulness : 컨텍스트에 근거해 얼마나 정확한가
- answer relevancy : 얼마나 관련성 있는가
검색시
- context precision : 쿼리 응답 후보로 가져온 청크 중 관련있는 문서가 상위에 랭크되어 있는가
- context recall : 쿼리 응답 후보로 가져온 청크가 검색 잘 되는가
대신 고질적인 문제인 Bias(편향)에 대해서는 주의
LLM as a judge 적용
작성중
'In progress' 카테고리의 다른 글
| [RAG 자기소개봇] 3. 검색과 응답 품질을 높이는 방법 (1) | 2026.01.28 |
|---|---|
| [RAG 자기소개봇] 2. 벡터 데이터베이스에 저장하고 검색 (2) | 2026.01.23 |
| [RAG 자기소개봇] 1. 문서를 RAG에 맞게 파싱 및 데이터 정제 (3) | 2026.01.20 |