용어 정리

Generalization

Fitting

Cross-validation

train, validation, test data의 비중을 어떻게 해야하나? — cross validation (kfold validation)
: train data 와 validation data를 k개로 나눠서 k-1개로 학습시키고 나머지 한개로 test
hyper parameter를 지정하는 clue가 없으므로 최적의 학습법 찾아야함
Bias and Variance (둘 다 low인 게 좋음)

Variance가 큰 모델은 비슷한 input이 들어와도 output이 다른것 (overfitting 될 확률 높음)
Bias가 큰 모델은 분산이 작더라도 평균적으로 봤을 때 표적값에서 벗어난 것

Bootstrapping
-: 신발끈을 들어 하늘을 날겠다
학습데이터가 고정되어있을 때 랜덤 서브샘플링을 통해 여러개의 모델이나 매트릭스를 만들어서 무언가를 하겠다

- 배깅 - 보통 앙상블 : 한개의 모델로 쓸 때보다 좋은 성능을 낼 때가 많음.
- 부스팅 - 여러개의 모델에서 n개의 결과를 뽑는 게 아니라 weak learner를 합쳐서 strong learner로 만듦
practical gradient descent methods
- stochastic gradient descent : 한개의 샘플로만 gradient를 계산해서 업데이트
- mini-batch : batch 사이즈의 샘플로 gradient를 계산해서 업데이트
- batch : 모든 데이터를 사용해서 그 평균으로 gradient 업데이트
batch size matters
한개는 너무 오래걸리고, 한번에 활용하자니 과부하고,, 단지 그 이유때문에만 쓰는 걸까?
아님. 배치사이즈가 너무 큰 걸 활용하면 sharp minimizers에 도달. 반대라면 flat minimizers에 도달. 차라리 flat에 도달하는 게 나음 - generalization performance가 일반적으로 높음

optimizer 고르려면,,, 왜 발전해왔고 무엇인지 알아야 하지롱
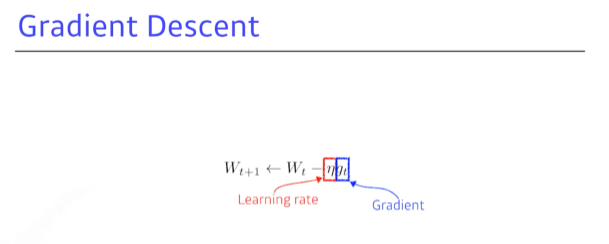
- stochastic gradient descent
- momentum
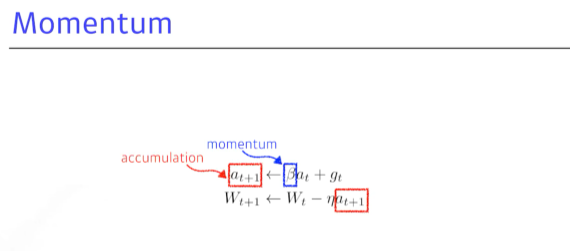
이전 배치의 정보를 활용해보자! B(하이퍼파라미터)가 모멘텀을 잡고, 다음번(t+1)때는 t때의 accumulation를 활용함. 한 번 흘러가는 gradient를 유지시켜주기때문에 왔다갔다 해도 일정 수준 보정해줌
- nesterov accelerate

Momentum과 비슷. 다른 점은 모멘텀이 현재 주어진 파라미터에서 gradient를 계산해서 그걸로 모멘텀을 누적했다면, NAG는 한 번 먼저 이동하고, 간 곳에서 계산한 gradient로 누적. 보다 봉우리에 빨리 도착할 수 있음.
- adagrad

많이 변한 파라미터는 적게 변화시키고 적게 변한 파라미터는 많이 변화 결국에는 G가 무한대가 되므로 뒤로 갈 수록 학습이 멈추는 현상이 생김. 이후 adadelta등으로 보완됨.
- adadelta

adagrad 보완. but 바꿀 수 있는 parameter가 많이 없어서 활용도는 낮음
- RMSprop

exponential moving average + stepsize 조합으로
- Adam

RMSprop + momentum. hyperparameter는 b1:모멘텀을 얼마나 유지시킬지
- b2:gradient squares에 대한 ema 정보, 에타(learnng rate), 입실론
Regularization
generalizaion을 잘 되게 하고 싶어서 규제를 거는 것. 학습을 방해하는 게 목적.
이점 : train 뿐만 아니라 test에도 잘 동작하도록 만드는 것.
- Early stopping

- Parameter norm penalty

neural network parameter가 너무 커지지 않도록, 제곱값을 줄이는 것. 함수의 공간 속에서 함수를 부드럽게 보자.
-여기에는 함수가 부드러울 수록 genalization performance가 높을 것이라는 전제가 있다.
- Data augmentation


어떤 식으로든 내가 가진 데이터를 지지고 볶아서 (ㅋㅋ) 데이터 수를 늘리려고 함. 왜냐면.. 일정 수준 데이터 수가 많아져야 딥러닝의 성능이 머신러닝보다 나아지기 때문.
- Noise robustness

- Label smoothing


dicision boundary를 찾아서 training data를 mixup
- Dropout

뉴럴네트워크의 weight의 일부를 ramdom하게 0으로 변환. 각각의 뉴런들이 robust한 feature를 잡을 수 있음. dropout ratio 가 0.5라면 50%가 0이 됨.


내가 적용하고자하는 layer의 statistics을 정규화시키는 것.
효과 - 뉴럴네트워크 각각의 레이어가 1000개의 파라미터로 된 hidden layer 근데 1000개 각 값에 평균을 빼주고 표준편차를 나눠줌. 결국 layer를 줄이는 것.
* 본 포스팅은 네이버 부스트캠프 AI Tech 3기 Pre-Course 강의를 정리한 내용입니다. https://www.boostcourse.org/onlyboostcampaitech3/joinLectures/329
'Study > Basics' 카테고리의 다른 글
| Python Object Oriented Programming (1) | 2021.12.29 |
|---|---|
| RNN (0) | 2021.12.29 |
| CNN (0) | 2021.12.29 |
| Neural Network & Multi-Layer Perceptron (0) | 2021.12.29 |
| Deep learning Preview (0) | 2021.12.29 |