Neural Networks
- 애매하게 사람의 뇌를 모방?
- 함수를 모방하는 approximator
Linear Neural networks
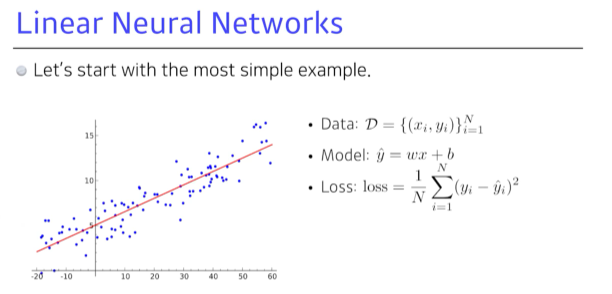

“어떻게 w와 b를 찾을까?” - backpropagation과 gradient descent/ascent update
stepsize를 자동으로 바꿔주는 optimizing이 필요 - adapted learning rate
차원이 다를 때
- matrix 사용
- 두 개의 벡터 스페이스 간의 변환 : 선형성을 가지는 변환이 있을 때, 그 변환은 항상 행렬로 표현된다.
딥러닝은 결국 neural network를 deep하게 쌓겠다는 뜻.


Nonlinear function
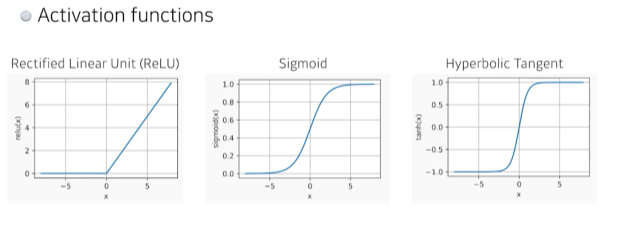
Universal approximators
Hidden layer가 하나 있는 Neural network 의 표현력은 어떤 대부분의 continues 하고 measurable 한 function을 거의 맞출 수 있다. - 단, 내 게 정확하다고는 볼 수 없다..
loss function

- MSE의 경우, 예측값에 비해 너무 튀는 데이터가 있으면 주의.
- CE의 경우, onehot vector로 표현되는 classification task 특성을 고려할 때 상대적으로 다른 값에 비해 특정 라벨의 아웃풋이 조금이라도 크기만 하면 됨. 이를 수학적으로 표현하기 어려우므로 CE를 사용함. 과연 나의 task에 ce를 사용하는 것이 최적일까? 를 고민
- MLE의 경우, 단순한 분류가 아니라 uncertainable한 자료까지도 얻고 싶을 때 사용할 수 있음.
* 본 포스팅은 네이버 부스트캠프 AI Tech 3기 Pre-Course 강의를 정리한 내용입니다. https://www.boostcourse.org/onlyboostcampaitech3/joinLectures/329424
'Study > Basics' 카테고리의 다른 글
| Python Object Oriented Programming (1) | 2021.12.29 |
|---|---|
| RNN (0) | 2021.12.29 |
| CNN (0) | 2021.12.29 |
| Optimization (0) | 2021.12.29 |
| Deep learning Preview (0) | 2021.12.29 |