Sequential Model
sequential data의 특성 상, 언제 그 데이터가 끝날지모른다. 몇개의 데이터가 들어올지에 상관없이 동작해야한다. 이것이 어려운 점으로 작용한다. 과거의 정보들을 고려해야하는 점이 첫 번째 어려움.
- Autoregressive model : 고려할 과거 정보를 특정 개수로 정해둠

- Markov model (first-order autoregressice model) : 가정하기에, 내 현재는 과거에만 의존하며, 이 때 과거는 바로 전에 국한. 근데 이게 말이 안됨. 내일의 수능 공부는 전날 공부에만 의존한다 라는 뜻이기 때문. 많은 정보를 손실하게 됨.

- Latent autoregressive model : 히든 스테이트가 과거의 정보를 요약해 담고 있고, 이것에 의존해 예측하는 것.

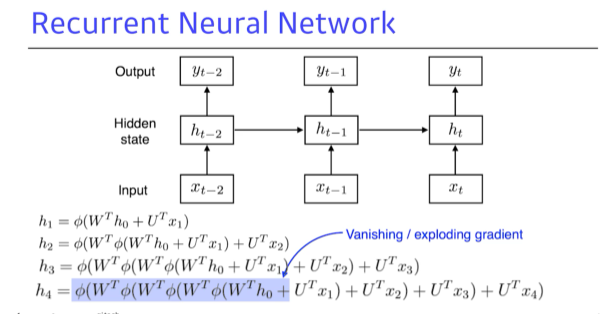
Recurrent Neural Network
- 학습이 어려운 이유?
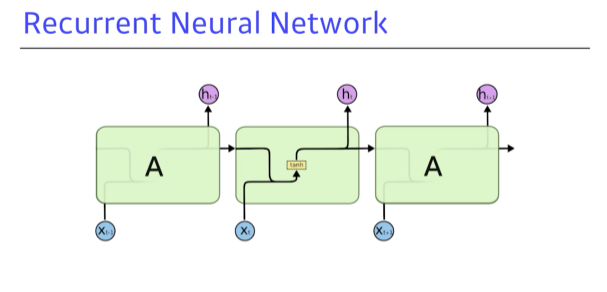
LSTM

각각의 컴포넌트는 어떻게 동작하나? 그리고 long term dependency를 어떻게 잡나?

x는 단어로 볼 수 있다. ht는 output, hiddenstate. 다음번에 적용됨.
previous cell state : 요약정보(아웃풋되지 않음). 컨베이어벨트 같은 것. 어떤 데이터를 어떻게 조작할지 판단해서 gate로 보냄
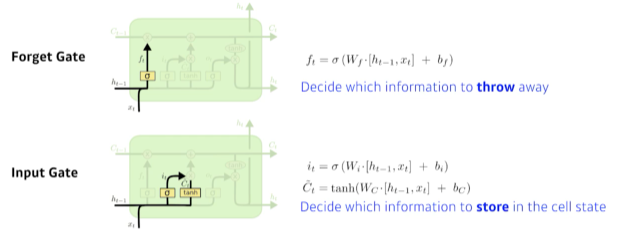

- forget gate 이전까지 들어온 정보를 현재입력을 바탕으로 지울지 결정 - sigmoid를 활용하므로 실수값.
- input gate 이전까지 들어온 정보를 현재입력을 바탕으로 cell state로 올릴지 판단
- update gate 위 두 정보를 취합하고 Ct 를 활용해 업데이트 후 Cell state로 보냄
- output gate 결과값 보냄
GRU
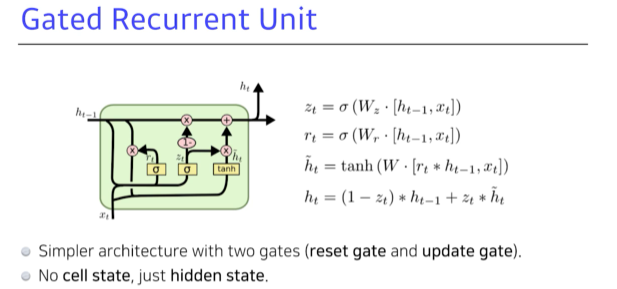
LSTM과 다르게 Gate 가 두개.
reset and update. lstm은 cell state가 흘러가고 그것을 한 번 더 조작해서 hidden state와 output이 나옴.
GRU는 hidden state가 곧 output.
즉 cell state가 없고 바로 hidden이 있음 + output gate가 필요없어졌음.
두개의 게이트만으로 lstm과 비슷한 역할을 할 수 있게 해 줌.
LSTM 보다 GRU가 Parameter가 적으므로,
Generalization performance가 일반적으로 올라가므로 성능이 좋아지는 경향이 있어 잘 사용함.
요약
RNN의 단점이 Long term dependence의 처리 문제 → LSTM. 근데 게이트가 3개라 파라미터가 많음.
→ GRU. 게이트를 2개로 줄여 성능이 향상됨.
* 본 포스팅은 네이버 부스트캠프 AI Tech 3기 Pre-Course 강의를 정리한 내용입니다. https://www.boostcourse.org/onlyboostcampaitech3/joinLectures/329
'Study > Basics' 카테고리의 다른 글
| Module and Package (0) | 2021.12.29 |
|---|---|
| Python Object Oriented Programming (1) | 2021.12.29 |
| CNN (0) | 2021.12.29 |
| Optimization (0) | 2021.12.29 |
| Neural Network & Multi-Layer Perceptron (0) | 2021.12.29 |